INTRODUCTION:
- Generally we write Rules when the required goal cannot be achieved by using transforms.
- It is a Code based Configuration option.
- A flexible framework that allows for very advanced or complex configurations.
- You can just think of it as basically just writing Java code.
- Technically it is Bean Shell however, it is much similar to Java, such that if you are familiar with Java, you will be familiar with Bean Shell.
- Just like with transforms, the use cases drive the need for a rule and thus we have many different rule types.
- Rules are very powerful but due to the IdentityNow architecture there are some special considerations regarding rules.
- Essentially, rules must be very high-quality code because they are being deployed into a multi-tenant service.
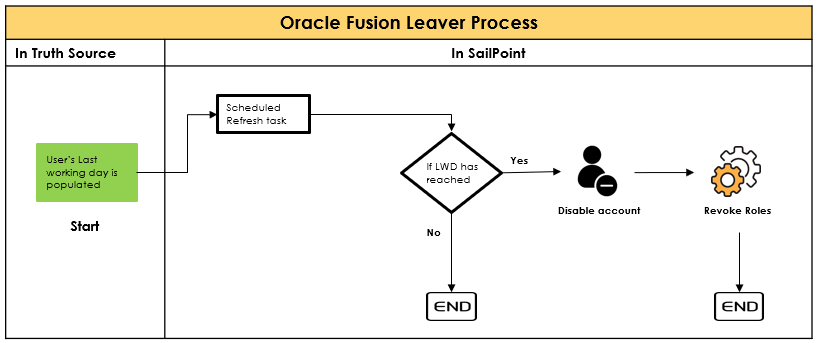
Rule Execution :
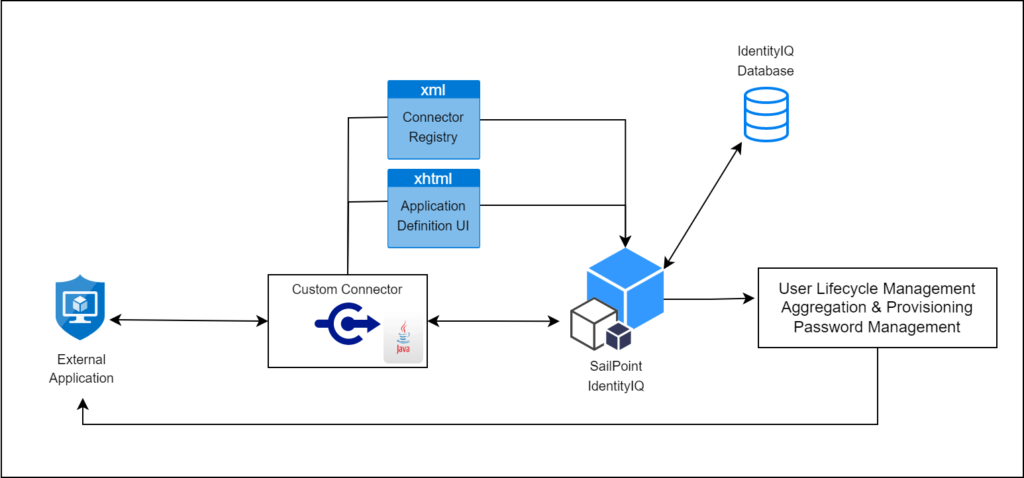
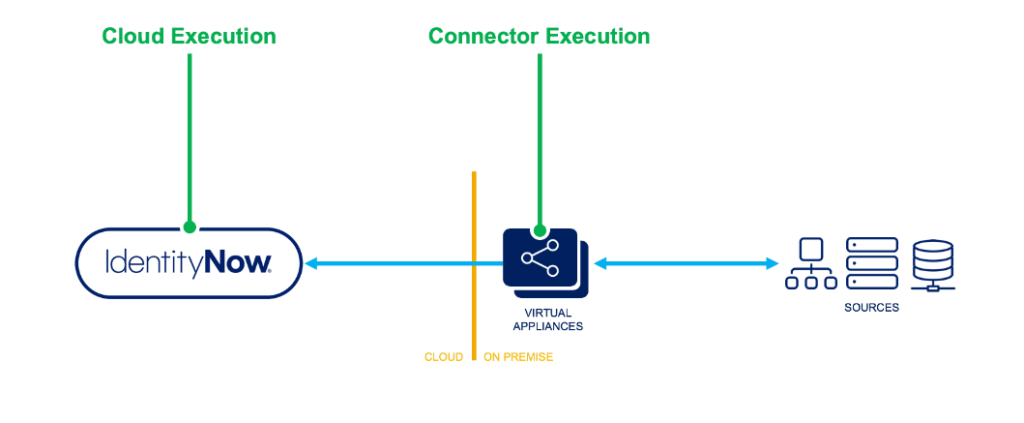
There are two primary places where you can execute rules one is CLOUD EXECUTION RULE & other one is CONNECTER EXECUTION RULE .
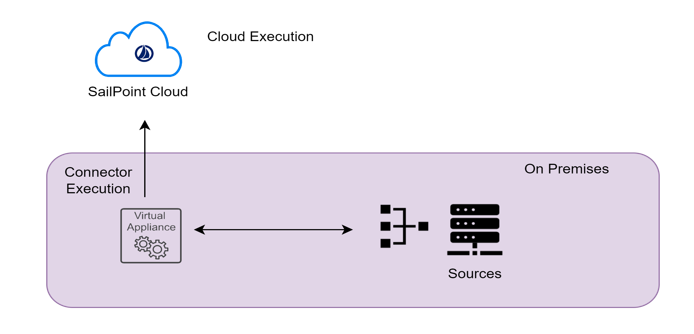
Let us have an overview on the difference between the cloud rules & connector rules
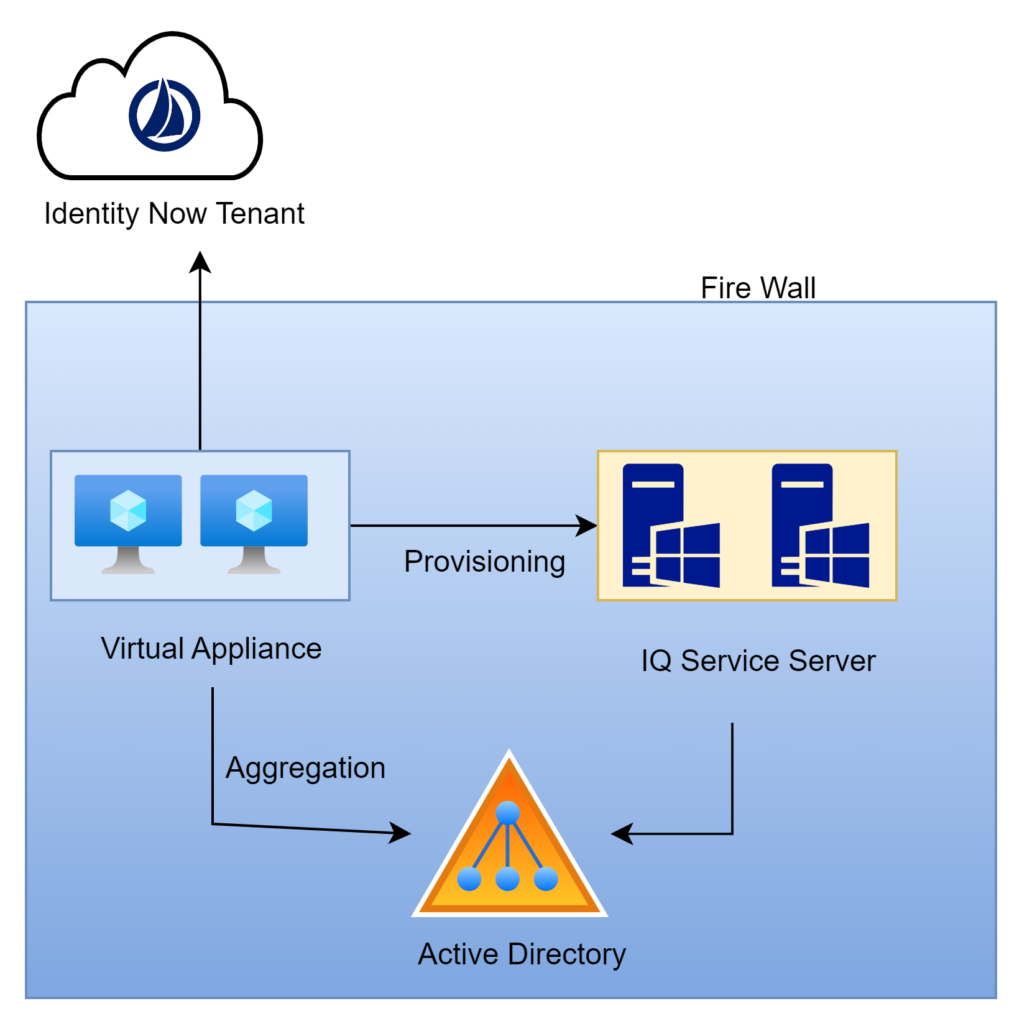
Cloud Executed rules are running in the cloud within the Identity Now tenant. Connector rules run on the virtual appliance which is on-premise inside the customer’s data center
Cloud Execution Rule :
- Cloud executed rules, as the name implies, are executed within the Identity Now multi-tenant environment.
- They typically have independent functions for a specific purpose. For example, calculating an Identity attribute value.
- Cloud executed rules typically need to query the Identity Now data model in order to complete their work.
- The rule might need to guarantee uniqueness of a value and it would generate a value and query Identity Now to determine if that value already exists.
- Access to any Identity Now data is read-only and you can’t make any calls outside of Identity Now such as a REST API from another vendor service.
- Because they run in a multi-tenant environment, the are put in a very restricted context and there is a great deal of scrutiny taken during the required review process for rules.
- We will cover the review process that is required when a cloud-executed rules is submitted later in the presentation.
- Of course, this all makes sense as you cannot allow rules to effect other tenants if they are poorly written.
- You also have to restrict the rules context so they can’t access any data from another tenant and things along those lines.
Connecter Execution Rule :
- Connector executed rules do not run in the cloud which is fairly obvious based on the name.
- These rules instead run on the VA itself. So they are running in the customers data center and therefore they are not running side by side with services from another tenant.
- They are usually extending the connector capabilities. The functions that they perform are quite complex.
- They do NOT have access to the Identity Now Data Model because they are executing on a virtual appliance.
- The huge difference here is that they are not subject to a review process by SailPoint. These rules can be uploaded via the REST API and are significantly easier to work with. With that said you still want these rules to be well written.
- The simple fact is that the possible negative effect of a poorly written connector rule is limited because it is not running within the Identity Now tenant.
SailPoint Provides us with six APIs to perform connector rule operations mentioned below :
- GET, LIST, CREATE, UPDATE, DELETE, VALIDATE are the APIs that are currently used for connector rule operations.
- A token with ORG_ADMIN authority is required to perform any operation.
Rule Examples
Example usage:
- Calculate complex identity attributes.
- Calculate complex account attributes.
- Provide connector logic
Connector rule Example – If there is a requirement to disable the account based on the number of entitlements or the account should be disabled automatically based on role revocation, this can be achieved by writing a connector rule
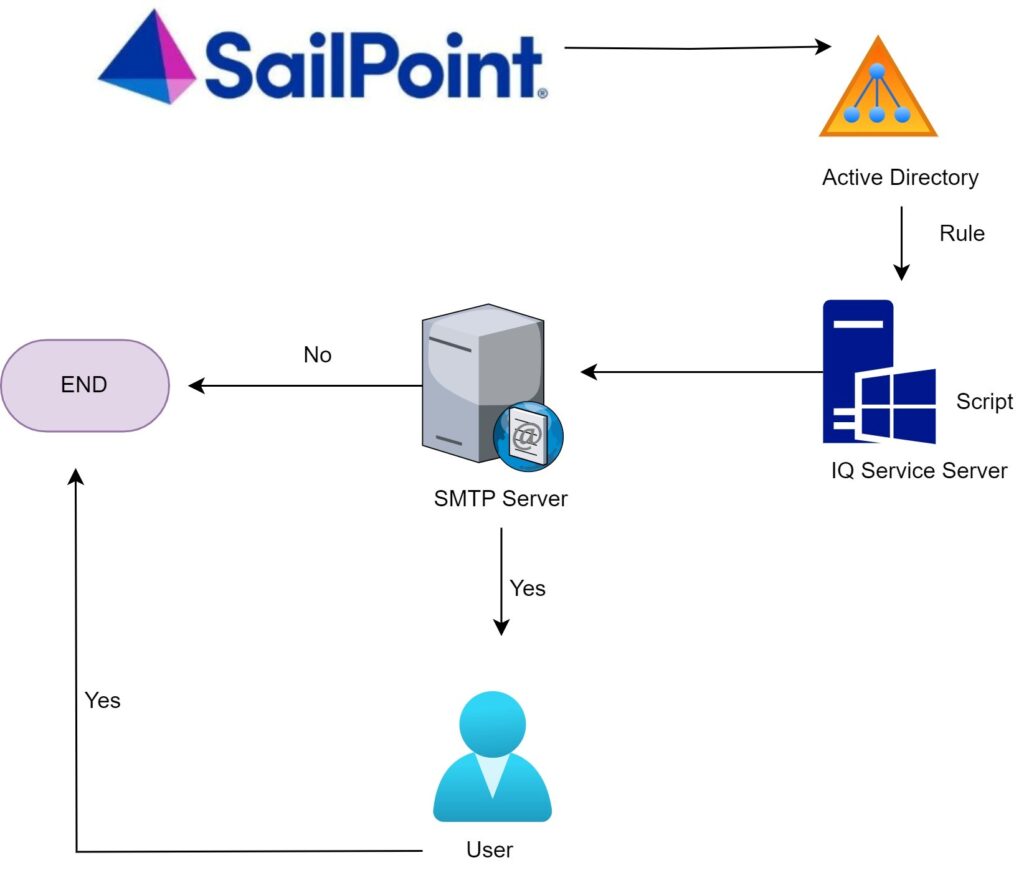
Cloud rule Example– This can be used for generating a unique email id which can scan the existing email id’s and generate a unique id for every joiner.
Please subscribe to our social media and stay updated with latest technology content. Thanks you.